Trigger warning: Conversation and possibly dark humour about fictional (and possibly not-so-fictional) people dying in car and train accidents.
How do you design a self-driving car to appropriately value human life? Can you use a Facebook group to speed the development of philosophical discourse?
The ‘Trolley Problem‘ is a problem in ethics, first known to be described in its modern form in the early 1950s. Basically, it boils down to the question:
If you have a choice between action and inaction, where both will cause harm, but your action will harm fewer people, is it moral to perform that action?
Interestingly, people answer this question differently, based on how active the action of harm is, the ratio of people hurt between the choices of action and inaction, and other reasons.
The astute will notice that this type of decision problem is a very common one, the most obvious being in military applications, but also vaccines (and invasive health procedures in general), firebreaks, and perhaps the canonical example, automobile design and manufacturing.
This type of decision making has become even more important with the advent of self-driving cars:
Overall, you would think that this would reduce your risk of fatality, but few people would choose that car, likely because it is a classic prisoner’s dilemma[1][2].
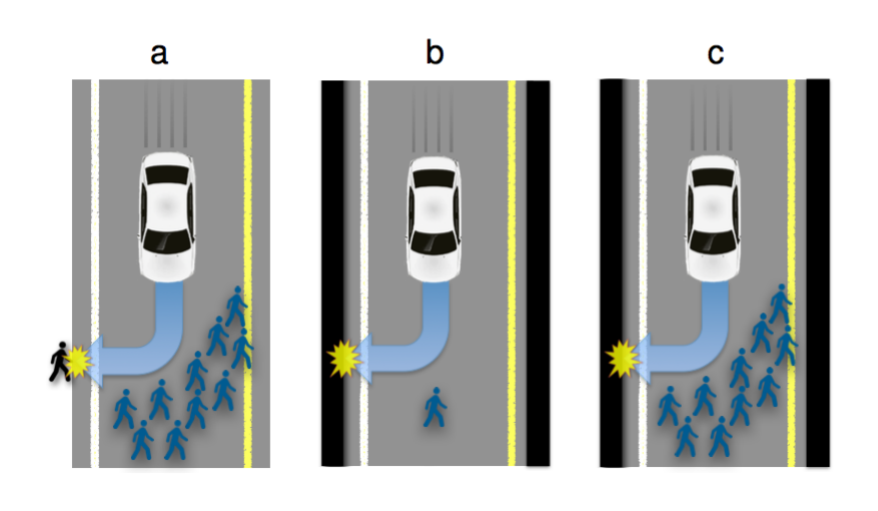
Personally, I think that much of this conversation is sophistry[3]. If one is truly interested in preserving life, the solution is not to convince self-driving cars to kill different people, but perhaps to have more stringent driving training requirements, to invest in fixing known problem intersections, to invest in better public transit.
So, if these conversations are not useful for anything else, they must be useful in and of themselves, and therefore must be Philosophy[4]!
One of the places that these conversations are occurring is the ‘Trolley Problems Memes Facebook page‘[5].
Now, you can argue that this page is purely for entertainment, but I think there’s a lot more hidden there. There is a fomenting and interchange of ideas, much faster and more fluidly than at any time in history. The person who writes the next book[6] on the ethics of decision making could well be influenced by or be an avid user of a site such as this one.
They may have started with Rick-rolling, but image macros are helping the advancement of human knowledge. Stew on that one for a while.
And while you’re thinking about that, something which ties it all together[7]:

[1]If everyone cooperates, overall they will receive a better result, but if any one of them betrays the others, they get an even better result, but everyone else’s result is much worse. This theoretically leads everyone to betray everyone else, leading to everyone having a worse overall outcome.
[2]People also like the feeling of control.
[3]Check out the article. Apparently, the Sophists were the first (recorded) right-wing think tanks.
[4]My undergrad Philosophy 101 prof. made the argument that because philosophy was not useful for anything else, it must be inherently be useful (and that that was better).
[5]Dark humour. You have been warned.
[6]And it might not even be a book! A blog post, even! 😀
[7]Not a deliberate pun.